{kind=link}
{kind=link}
The first step is to formulate the machine learning task as a mathematical optimization problem.
Gradient descent is an optimization algorithm used primarily to minimize a function.
What is a convex optimization problem?
Convex Optimization Problem
This refers to a specific subset of optimization problems where the objective function is convex, and the feasible region (if any constraints exist) is also a convex set. Convex problems have the property that any local minimum is also a global minimum, which makes them particularly nice for optimization.
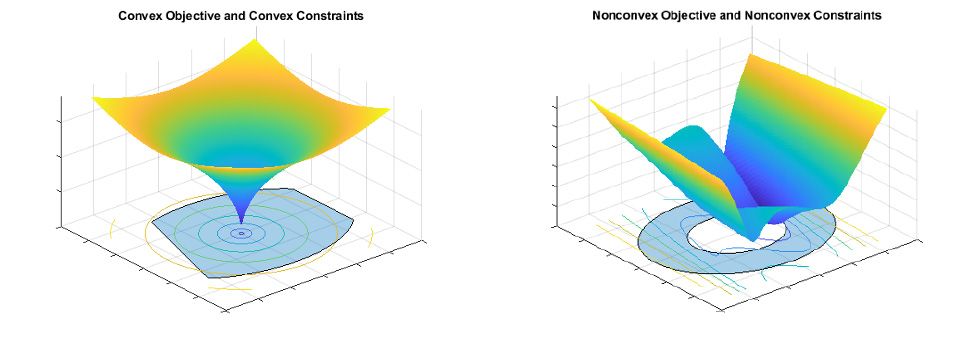
What is a non-convex optimization problem?
https://youtu.be/iudXf5n_3ro?si=Jndenbr03_bTb-8w
What is the goal of gradient descent?
The name of the game is simply to find the values of the weights and biases which minimize the cost function.
Adam Optimisation
Adam optimization
Adam can be looked at as a combination of RMSprop and Stochastic Gradient Descent with momentum. Stochastic gradient Descent
What might the cost function be for this neural network:
https://youtu.be/qg4PchTECck?si=_jYLIrrHJoXosfuB
Why do we need an algorithm for this? Can’t we just plot the function and point to the minimum?
Iterative
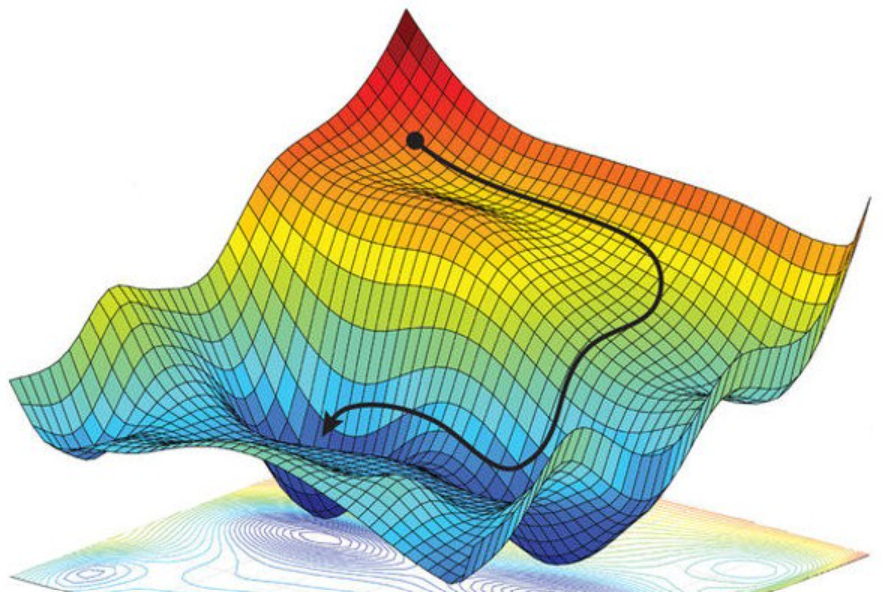
Explain the vanishing gradient problem
what is the difference between the vanishing and exploding gradients problem
What are some methods for mitigating the vanishing gradient problem?
Prove using the Cauchy-Schwarz
Let me do a ‘plain-English’ proof, using only logic and no mathematics.
Indeed, there’s even a sense in which gradient descent is the optimal strategy for searching for a minimum. Let’s suppose that we’re trying to make a move Δv in position so as to decrease C as much as possible. This is equivalent to minimizing ΔC≈∇C⋅Δv. We’ll constrain the size of the move so that ‖Δv‖=ϵ for some small fixed ϵ>0. In other words, we want a move that is a small step of a fixed size, and we’re trying to find the movement direction which decreases C as much as possible. It can be proved that the choice of Δv which minimizes ∇C⋅Δv is Δv=−η∇C, where η=ϵ/‖∇C‖ is determined by the size constraint ‖Δv‖=ϵ. So gradient descent can be viewed as a way of taking small steps in the direction which does the most to immediately decrease C.
What is online learning?
Also known as incremental learning.