{kind=link}
{kind=link}
People get into machine learning and think there's nthing left to do because we have tensor flow.
https://github.com/Sroy20/machine-learning-interview-questions/blob/master/list_of_questions_deep_learning.md
The taxonomy
Used to solve extremely non-trivial problems. I mean just THINK about how you’d try and solve some of this stuff with if/else statements
We’ll introduce some new terminology.
Hopefully by the end, you will understand these diagrams:
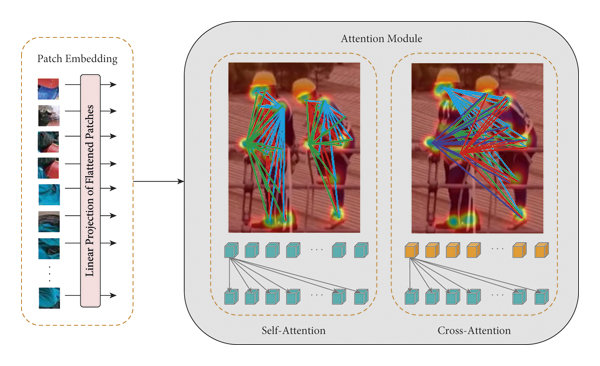
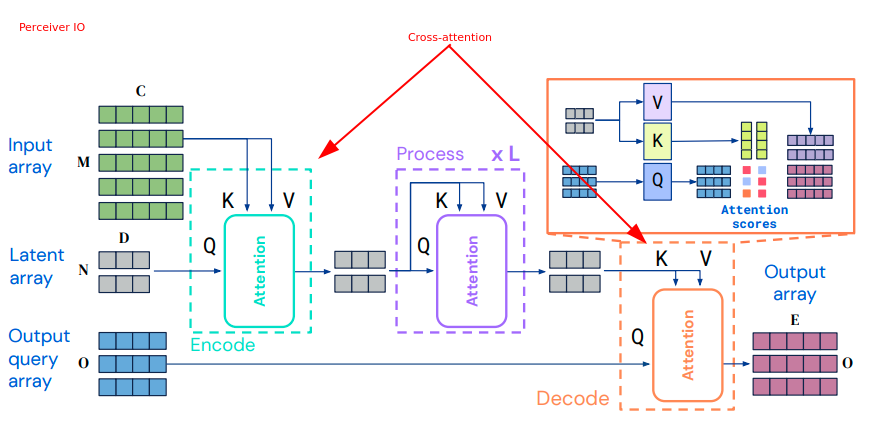
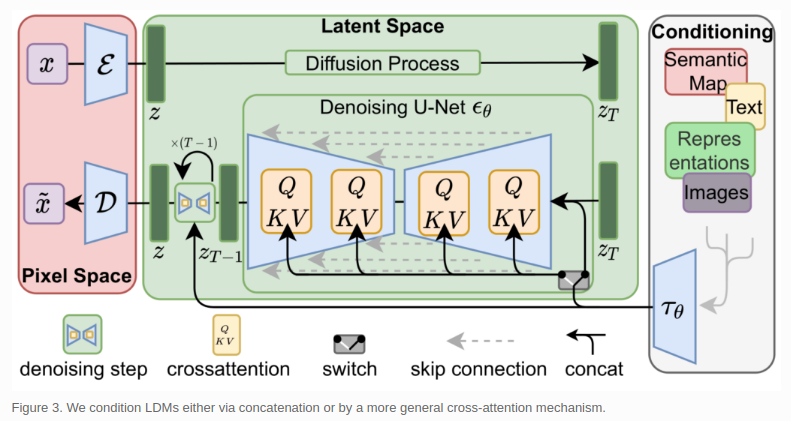
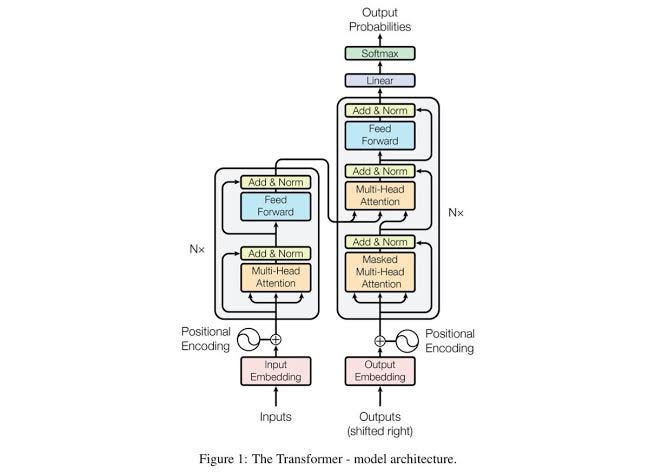
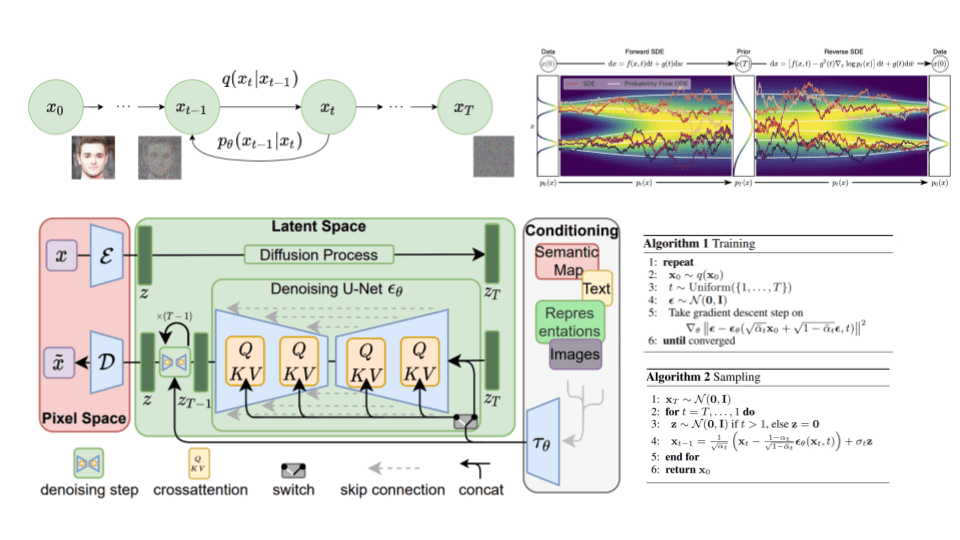
Is it always best to use deep learning model over a traditional model, if possible?
No. Read this question.
(A) How could you use these methods for facial recognition?
Answer 1: You could extract features like eyebrow colour, eyebrow shape, and then train an ensemble model like Adaboost to classify
Answer 2: Enter deep learning
Deep learning figures out what the best features are, and automatically extracts then. They extracts features that humans could never even comprehend, nor extract themselves. And they are the best ones.
The underlying framework is identical. To classify a fruit using explicit features, we might want the following things:
For example, a model trained to classify cars may see these features

A very general image recognition model trained a dataset like IMAGENET might see these:

And a facial recognition model

Notice how these features could never be explicitly engineered by a human being. The deeper in the network, the less interoperable they become.
This is where Deep Learning comes in. Automatic feature extraction
(A) Deep learning seems really good… what’s the catch?
Deep learning models are extremely data hungry
(A) Your manager comes to your desk and tells you that your great plan to fund 1 million. What’s your new strategy?
Active learning.
Q6) What is a corpus?
too specialist
What is an embedding?
Activation Function Backprop Decoder Dimensions Discrimanator Epoch Feature set feedback loop Generalisation Heurisic hidden Layer
Inference Learning rate loss pretrained model Sequence to sequence task Sigmoid function Softmax Trasformer
(ascii or doodle, simple in middleof page) Data structures, algorithms, and Data
- What is a parent teacher network
- What is distilling
- (data science book can’t hate it’s good)
Neural Networks -> LLM
Q1) In your own words, explain what a neural network is
- A neural network is a function approximator
- A ‘function’ is anything that takes an input, and produces an output
- (e.g
Handwritten Digits -> Digit from 1-10) - (e.g
A word prompt -> A 512x512px image)
- It approximates the function using a network of much smaller, simpler ‘neurons’ which are themselves also a type of function (best seen with a diagram)
- Multiple inputs + a bias, some activation function, single output
- How does it fine tune these individual functions so that the larger function of the whole network is accurate? Backpropogation
https://youtu.be/0QczhVg5HaI?si=RyXl_bpNOsxEf62o
https://youtu.be/aircAruvnKk?si=G11HUoz-xhKFY_nJ
https://youtu.be/bfmFfD2RIcg?si=yIdjlFMA8jLk6twc

QX) What is transfer learning?
When you invest 10,000 hours into learning the drums, and then decide to try the piano, and pick it up in a few weeks (because you learnt rhythm, parts of music-reading, and hand eye coordination from the drums) - that is transfer learning.
☞ Similarly, in machine learning, transfer learning involves taking a pre-trained model (a model trained on a large dataset) and using it as a starting point to train a new model on a related task or dataset. Instead of starting the learning process from scratch, you leverage the patterns and knowledge the model has already learned. E.g; maybe your image recognition model already knows what a dog is… so…
QX) What are the synergies (benefits)?
- Data efficiency - can achieve more with less labelled data
- Reduced training time
- Improved performance
QX) Are you familiar with Large Language Models?
QX) Artem’s video
QX) You are building a resume parsing model. Explain how you would employ Deep Learning in order to classify a string of text ‘Florida …’ as either a Job Title, Place, ...
- Create embeddings
- The brains
What is fine tuning?
Finetuning
Finetuning is no different than training, we just make sure to initialize (the weights and biases) from a pretrained model and train with a smaller learning rate.
What is the soft max function?
What is the argmax function
The argmax function is related to, but distinct from, the ‘max’ function. While the ‘max’ function returns the maximum value in a set, the argmax function returns the index of the maximum value. This is a subtle but important difference. Let’s explore how argmax works:
How argmax Works
-
Inputs:
- The primary input to
argmaxis a collection of values, typically an array or a tensor. This collection can be multi-dimensional. - Optionally, you can specify the dimension (or axis) along which to find the index of the maximum value. If not specified,
argmaxtypically operates on the flattened array.
- The primary input to
-
Process:
argmaxscans through the given collection of values.- It keeps track of the highest value found and its index.
- If the collection is multi-dimensional and a specific dimension is specified,
argmaxis applied along that dimension. For example, in a 2D array, specifying a dimension of 0 will applyargmaxto each column, and specifying a dimension of 1 will apply it to each row.
-
Outputs:
- The output of
argmaxis the index (or indices, in the case of a multi-dimensional array) of the maximum value. - The nature of the output depends on whether the input is a flat array or a multi-dimensional array and whether a specific dimension was specified.
- In a flat array, the output is a single index. In a multi-dimensional array, the output can be an array of indices, one for each row or column (or along another dimension, if specified).
- The output of
Example
Consider a 2D array:
[
[1, 3, 5],
[2, 4, 1]
]
- Using
argmaxwithout specifying a dimension will return the index of the maximum value in the flattened array, which in this case is5with a flat index of2. - If
argmaxis used withdim=0(along columns), it will return[1, 1, 0], indicating the indices of the maximum values in each column. - With
dim=1(along rows), it returns[2, 1], indicating the indices of the maximum values in each row.
In Summary
argmax is particularly useful in machine learning and data analysis contexts where not just the maximum value is important, but also the location (index) of that value in a dataset. In classification tasks, for example, the index represents the class label, so argmax is used to convert network outputs (scores/probabilities for each class) into predicted class labels.
Why is cross entropy used instead of the sum of squared residuals (SSR) as loss function for neural nets.
It works by... treating the output. Must be softmax'ed first, is argmax by default.
- Log?
- Why is it simiplified form?
- Used when . works for binary classes
- what is used for nn’s which output a value
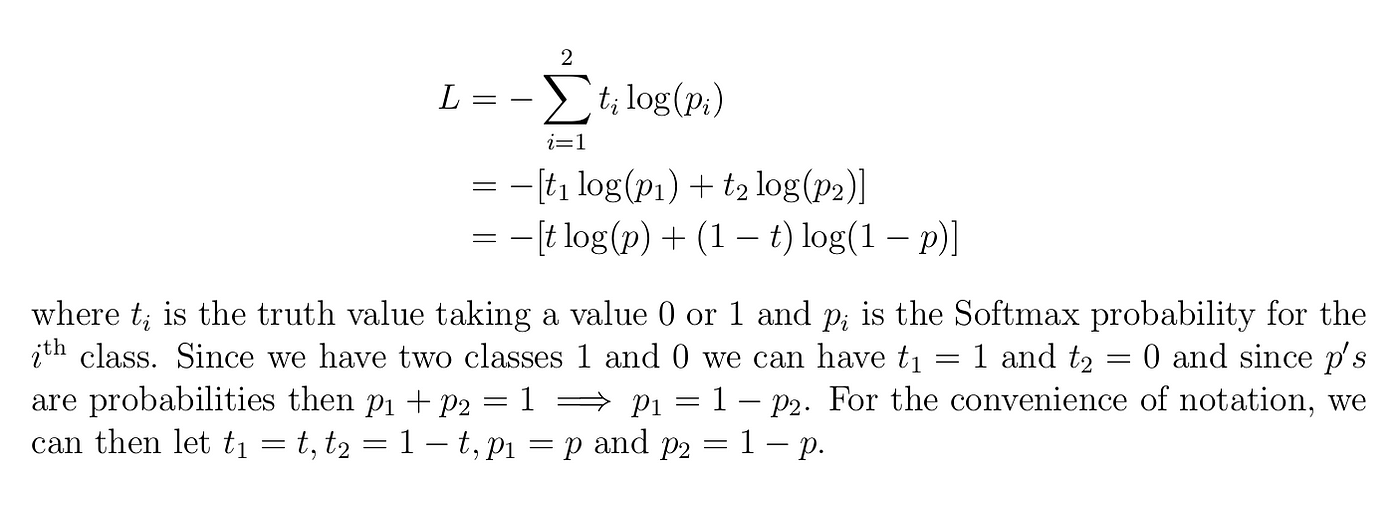

Again, quickly state the purpose of regularization, then explain some ways that NN’s are commonly regularized.
Prevents overfitting… has the aim of making the model generalize better… more robust
Regularization in neural networks is a technique used to prevent overfitting, where the model performs well on the training data but poorly on new, unseen data. Overfitting is a common problem in complex models with many parameters, such as deep neural networks. There are several methods for regularization:
-
L2 Regularization (Weight Decay): Adds a penalty term to the loss function proportional to the sum of the squares of the weights. This encourages the model to keep the weights small, which can lead to a simpler model that generalizes better.
-
L1 Regularization: Adds a penalty proportional to the absolute value of the weights. This can lead to sparse models where some weights become exactly zero, effectively performing feature selection.
-
Dropout: Randomly sets a fraction of input units to zero at each update during training, which helps prevent over-reliance on any one node and promotes distributed representations.
-
Early Stopping: Involves monitoring the performance of the model on a validation set during training and stopping the training process once the performance starts to degrade. This ensures the model doesn’t overfit the training data.
-
Data Augmentation: Generating new training samples by altering existing ones (e.g., rotating, scaling, or cropping images in a vision task). This can provide more diverse data for training and helps in learning more general features.
-
Batch Normalization: Normalizes the input of each layer to have a mean of zero and a variance of one. This can stabilize and speed up training, sometimes reducing the need for dropout.
-
Noise Injection: Adding noise to inputs, weights, or even the outputs of layers during training can also act as a form of regularization, making the model more robust.
-
Reducing Network Size: Simplifying the architecture (fewer layers or nodes) can reduce overfitting since there are fewer parameters to learn.
-
Ensemble Methods: Combining the predictions from multiple models can improve generalization and reduce overfitting. Techniques include bagging, boosting, and stacking.
-
Learning Rate Schedules: Adjusting the learning rate during training (e.g., reducing it gradually) can help the network to converge to a better solution.
-
Regularization via Attention Mechanisms: In some architectures, particularly in sequence modeling and NLP tasks, attention mechanisms can help the model focus on the most relevant parts of the input, reducing overfitting.
Different methods can be combined depending on the specific problem and the nature of the dataset. The choice of regularization techniques is often empirical and may require tuning through cross-validation.
Can you explain the concept of X shot learning? (zero-shot, one-shot, two-shot, …)
Can you explain the concept of transfer
https://chat.openai.com/share/f94c8196-6de7-4c66-b8c3-065d4a67987c